
Why Create a Regex Replacement?
I’ve said before that I really enjoy reading the posts about Oil Shell. I have a lot of enthusiasm for the goals of that project, and it’s great to be able to read about a project as it evolves. A recent post covered the raison d’être for Oil Shell and the Oil Language, and inspired this post. Go read that post now if you want — we will be here when you get back. 😁
Table of contents
- Why Create a Regex Replacement?
- The structure of the Rosie project
- Frequently Asked Questions
- Design
- Why use Parsing Expression Grammars (PEGs)?
- Why not use one of the many existing PEG libraries?
- PEG parsing uses a lot of memory, right?
- The JSON output is so verbose!
- How do I put captures in my RPL pattern?
- Is the concept of 'output encoder necessary? Regex does not have these.
- RPL looks like overkill. Wouldn't something simpler work?
- Performance
- Design
- Current State of the Project
- Conclusion
- Notes
Why Create a Regex Replacement?
It’s easy to joke about how frustrating regex can be to write, and how impossible they are to read.
Some people, when confronted with a problem, think “I know, I’ll use regular expressions.” Now they have two problems. (Jamie Zawinski 1)
Here’s the xkcd version of that thought:

However…
Regular expressions have been such a useful and practical tool in computing that we still use them today, in 2018. It has been 50 years since Ken Thompson showed how regular expressions could be a text searching technique that is both powerful and efficient 2.
Clearly, regex are ubiquitous because they fill a persistent need. Today, we rely on regex in so many ways, including:
- lexical analysis for the vast majority of programming language parsers;
- lexical analysis for Natural Language Processing;
- lexical analysis for parsing serialized data formats (JSON, yaml, XML, etc.);
- searching within text editors;
- operations, in scripts that search and manipulate configuration files, log files, the output of other programs, and more;
- development, in tools that manage source code, issues, builds, and tests.
So we have arrived, in 2018, at a point in time when we reflexively reach for regex despite 50 years of advances in Computer Science. In 2015, I faced a data mining problem for which regex seemed unsuitable 3. I searched the open source community for tools that would meet my requirements, and found essentially none. Roughly, I wanted:
- a pattern language less cryptic than regex, so that it would be easier to read, write, and maintain patterns;
- language independence, so that I would not be forced to program in Perl (ever) or Ruby or Scala or the language du jour;
- composability, so that I could reliably build complex patterns out of simpler ones;
- more power than regex, in particular the ability to match recursively-defined data 4;
- static analysis, especially to find errors before run-time5 and to perform dependency checking before deployment;
- good matching performance, both asymptotically in the size of the input, and in absolute terms;
I searched the research community for ideas and found the concept of Parsing Expression Grammars (PEGs) 6, which led me back to the open source community to examine the lpeg implementation 7, which is a module for the Lua language.
Parsing Expression Grammars are only a starting point
PEGs seemed to be a good building block, with a formal foundation and several well-analyzed algorithms for using them. With the lpeg implementation for Lua, I was able to avoid the large space requirements of “packrat parsers” for a lean and elegant implementing using a “matching virtual machine” approach.
I knew I could wrap the lpeg implementation, along with Lua (upon which it depends), into a single shared library (object file) of perhaps 500Kb in size. And, with its liberal MIT license, I would be able to improve and enhance lpeg to suit my needs.
With the decisions to build on PEGs, to start with the lpeg implementation, and to produce a shared object library, most of my requirements appeared achievable. The big open questions at this point were:
- What should the syntax look like? It must support development and maintenance of pattern expressions by many people over the long life (and many developers) of the projects that use them.
- How can I ensure that expressions are composable, so that developers are not always writing patterns from scratch (or copying them from Stack Overflow)? We should be able re-use other people’s patterns and build on them.
- Is it possible to enable static analysis, typified by the develop/compile/run cycle, while simultaneously supporting dynamic interpretation of patterns written on the fly, e.g. on the command line?
- Will my employer, IBM 8, recognize that the success of this project will depend on the creation of a user community, and that such a community is best enabled by releasing this project as open source under a liberal (MIT) license?
Fortunately, the answer the last question was yes. So, during 2016-2018, I designed the Rosie Pattern Language and wrote its implementation, and iterated on both. In the process, I answered the open questions above. The results are embodied in Rosie version 1.0.0.
The goal of the Rosie project
I’ll sum up the goal of the Rosie project this way: Provide an alternative to regular expressions for situations that require more expressive power, better maintainability, and/or opportunities for static analysis.
The goal is not to displace regular expressions or make them obsolete, but to provide an alternative for some uses of regex. Edit August 15, 2023: Today I would say that our goal is to replace most if not all uses of regex. Even on the command line, where the compact regex syntax is convenient, the ability to access namespaced libraries of patterns may win the day.
The structure of the Rosie project
The earliest notion of what would become Rosie and RPL was the thought, “I’ll write a shared library for PEG-based matching, and provide bindings to the programming languages that we want to use.”
It quickly became apparent that this was insufficient to meet my needs. When I look back over the requirements I set for this project, the reason is obvious, though it was not at the time. Most of the requirements are for a language, not a library.
Through the early iterations, the idea of a language for PEG-based matching coalesced into Rosie Pattern Language (RPL). The first implementations of an RPL compiler and run-time are combined in the Rosie Pattern Engine. Let’s look briefly at the language and the implementation, in turn.
RPL (Rosie Pattern Language)
The experience of using RPL was designed to resemble the experience of programming. The language was designed in service of readability, maintenance, and composition. Composition means the ability to build new patterns out of existing patterns, and this enables many good things, such as:
- We can solve complex problems by composing solutions to simpler problems. (This is possible with regex, if they are used very carefully, but the general case is fraught.)
- Good solutions to common matching problems can be collected into a library, so that developers can easily share them. Sharing is especially valuable for patterns that recognize syntax defined by standards, e.g. timestamps and network addresses and other formats governed by IETF and other groups.
- A notion of abstraction for patterns, though inchoate, is apparent. Just as with software libraries, where we routinely use library functions without knowing (or understanding) details of their implementation, we wish to have an analogous notion for patterns.
Regarding the notion of abstraction, we want to reuse patterns from libraries without knowing details of how they are written. Often, this is possible. When it is not, we need to see how a pattern is written before we can use it. And when this happens, there is an opportunity: Can we identify the knowledge gained from reading the implementation, and can we enhance our concept of a pattern library to expose that knowledge in the future? (There are analogous questions with software libraries, but I suspect the restricted domain of textual pattern matching will readily admit a “leak-proof” abstraction if someone takes the time to investigate the topic.)
Relationship to regex: syntax
Regex have a very compact syntax, which is great for the command line and other
“on the fly” pattern writing, like searching in a text editor. Although RPL
syntax is more verbose, it borrows familiar syntax from regex when the concepts
are the same. This is apparent in the repetition operators, like *, +, and
?, and in character classes, like [[a-z][0-9]].
Another similarity is the use of adjacency as an operator. In regex, a sequence
of expressions is formed simply by concatenating them together. The same is
true for RPL, but since whitespace is not significant in RPL, there can be
whitespace between the elements of a sequence, like in "nameserver" net.ip,
which is a sequence of two patterns, the literal "nameserver" and the name
net.ip.
And that brings us to the second biggest difference, syntactically, between RPL and regex: named patterns. To compose patterns in RPL, we must be able to refer to them by name, so RPL provides constructs that bind names to pattern expressions.
Finally, the most obvious surface distinction between RPL and regex is that RPL follows the PEG format of using a forward slash for its choice operator, instead of the vertical bar used in regex. The slash was selected because the choice operator in PEGs is not the same as the one in regex: choices in PEGs (and RPL) are ordered, whereas in regex they are unordered alternatives.
Relationship to regex: semantics
The semantics of RPL are based, ultimately, on those of Parsing Expression Grammars. They differ from regex in that RPL expressions are both greedy and possessive. Greedy expressions match the longest possible sequence, and possessive expressions are not re-evaluated once matched.
Regex are typically greedy and not possessive, but there is lots of variation across implementations about which variations are allowed. The fact that regex are not possessive means that the match of any sub-expression may be re-evaluated in an effort to make the larger expression succeed. (This is often implemented by backtracking.)
Taking the larger view, the “languages” (sets of strings) recognizable by PEGs contains those recognized by regular expressions. In other words, anything that can be matched with a regex can be matched with a PEG.
In a 2014 paper, Medeiros et al. 9 construct an algorithm for transforming simple regular expressions into equivalent PEGs. In 2017, an undergraduate at North Carolina State University implemented the algorithm using RPL as its output format, demonstrating that simple regex can be effectively transformed into RPL 10.
An enhanced version of that implementation could be a useful tool for migrating from regex to RPL. However, there are literally dozens of popular regex implementations, each with its own extensions and semantic quirks. Which should be supported, and with which features? How should such a tool be distributed and used? This is an exciting project in itself, and if you are interested in working on it, we would welcome collaborators!
Implementation: Compiler and Run-time
Having selected the lpeg library as the PEG implementation, and being already familiar with the Lua language, I began coding Rosie in Lua. Initially, the language (which would become RPL) was very simple, so it was easy to write a compiler that transformed pattern expressions into lpeg expressions.
The lpeg expressions were built incrementally via function calls to the lpeg library. When the user wanted to match an expression against some input data, the Rosie implementation would call the lpeg library to (1) further compile the lpeg expression into instructions for the lpeg matching virtual machine (mvm), and then (2) start the mvm to do the matching.
In this way, lpeg expressions (represented internally using lpeg abstract syntax trees) form the intermediate language (IL) for Rosie.
The Lua interpreter is written in C, as is the lpeg library, and is designed to
be embedded into larger applications. Consequently, it was straightforward to
write librosie, a C library that embeds both Lua and lpeg, exposing an API for
compiling and running RPL.
The RPL compiler
As RPL matured during 2016-2017, the compiler became more complex, and at one point I rewrote it from scratch. At other times, it was significantly refactored. Compiler writers will understand that good error reporting is difficult, and a surprising amount of code is needed for it. Today, in version 1.0.0, the Rosie compiler has a reasonable set of error reporting mechanisms, but more work is needed to produce helpful messages.
It was a joy to develop the RPL compiler in Lua. The RPL language, and therefore the compiler, evolved by irregular leaps, and the flexibility provided by Lua made large-scale changes manageable. Dynamic typing, higher order functions, and automatic memory management provided much of the needed flexibility.
But also, the ad hoc module system in Lua turned out to be a boon. Lua reifies
environments as tables, exposing the tools needed to roll your own module
system, which I did. I used the concept of
“duck typing” to allow two (or
more) modules to expose the same interface, so that I could “boot” Rosie with,
say, the working compiler, and then switch over to a new refactored compiler for
testing. Even now, in version 1.0.0, there are Lua modules like parse_core
and parse, which parse different versions of RPL but expose essentially the
same interface.
Now that the definition of RPL has settled into a form that I hope will not change for a long time, the benefits of having an RPL compiler written in Lua are less relevant, and the penalties are more apparent. The penalties are primarily speed and inability to do some static analyses. To be clear, Lua is fast. But I wrote the RPL compiler using lots of assertions, custom run-time type checks, try/catch constructs, and the retention of lots of intermediate data (for debugging the compiler). All of these slow down the RPL compiler.
Going forward, beyond version 1.0.0, the slow pieces of the RPL compiler will be refactored. If enough developer-hours were available, I would seriously consider re-implementing the compiler in a language like Go, which has static typing (and interfaces), a simple error mechanism, and good concurrency support. Plus, I would not have to write my own module system, try/catch implementation, or libraries for lists, sets, structs, and more. (In other words, there would be less custom code in the compiler.)
The RPL run-time
The RPL compiler, as described above, compiles RPL into an IL that is further processed by the lpeg compiler. This is the compile-time phase. Once the IL has been transformed into instructions for the matching virtual machine, it can be executed, i.e. matching can be performed. Matching is the run-time phase.
As I mentioned earlier, the compiler and run-time began as a single program, with components implemented in Lua and C. During 2017, I made several changes to the lpeg code, and more changes are on the “to do” list. Mostly, the changes were enhancements to support Rosie/RPL, but some were changes to separate lpeg from Lua. In fact, it is no longer appropriate to call the run-time matching engine lpeg – it began as lpeg, but has been modified, so we will start calling it rpeg instead.
Rpeg was lpeg initially, and lpeg was tightly integrated with Lua. Not only could lpeg functions be called from Lua, but the lpeg implementation leveraged Lua for some data structures (tables), error reporting, and other functionality. For the Rosie project, we would like to be able to separate the RPL compiler from the run-time code. The plan is to finish divorcing rpeg from its Lua dependency, so that the matching virtual machine (in C) can be used stand-alone, without the RPL compiler (written in Lua). A key part of this effort will be to save the compiled RPL to disk, and read it back into a stand-alone matching vm.
A small run-time should enable faster loading and a smaller memory footprint, not to mention the opportunity to have alternate implementations of the run-time. For example, it would be nice to have an implementation for the jvm, for use by Java, Scala, or Clojure. (The RPL compiler could be used off-line, in such an environment, or could be called using the foreign function interface of the jvm. Since compilation occurs infrequently compared to matching, penalties for using the ffi will amortize out of most use cases.)
Separating the RPL compiler from the run-time is a current Rosie sub-project, and we welcome collaborators!
Frequently Asked Questions
Design
Why use Parsing Expression Grammars (PEGs)?
(1) I wanted an approach that had a formal basis, so that we can (in future) prove useful properties about RPL expressions. For example, we want to prove correct the transformations and optimizations that are done by the RPL compiler.
(2) As mentioned already, there is a common need to parse recursively-defined structures, and PEGs can do this.
(3) Context Free Grammars are expensive to parse, whereas PEGs can be parsed in linear time in the input size.
Why not use one of the many existing PEG libraries?
There are some really good PEG libraries available, but all of the ones I examined when I started Rosie were integrated with a particular programming language. In other words, there’s a good Python PEG package, a good Java package, a good Lua package… but I wanted a language-independent solution.
I built upon the Lua lpeg package in part because it’s implementation is elegant and lends itself to the kinds of extensions and modifications that I anticipated making. Also, Lua is easily embeddable in a (shared C) library, which is not practical with Python, Javascript, Java, or many other languages.
PEG parsing uses a lot of memory, right?
One approach to PEG parsing
(“packrat parsing”) is
sometimes criticized for consuming a lot of memory. But in return, packrat
parsers take only linear time in the input size, no matter what the pattern
looks like. By contrast, an approach like lpeg requires linear time in the
input size, given a fixed pattern. The time is super-linear in the “star depth”
of the pattern (a measure of pattern complexity).
Edit August 15, 2023: The
analysis is more subtle than I knew back in 2018. In regex, the star depth is
the maximum nesting depth of Kleene star expressions. The PEG star operator is
possessive, unlike Kleene star in regex, and so does not contribute to the star
depth. The equivalent to star depth in a PEG grammar is a measure of nested
recursive expressions, the details of which we leave for a future post.
In practice, the lpeg approach is a good choice because the vast majority of text-matching patterns require only linear time. Furthermore, the possibility of longer matching times can be identified by static analysis of the pattern being used (which makes the tradeoff visible to the user).
Finally, I expect that the lpeg approach can be enhanced with memoization, parameterized by how aggressively the user wants to reduce the running time by trading off a higher use of memory. This would be a very interesting project to implement – conceptually not difficult but probably with practical challenges.
The JSON output is so verbose!
Yes, it is. However, Rosie can provide output in many forms, and not all of
them are so verbose. Internally, the Rosie matching process produces a data
structure that is isomorphic to the Rosie JSON output, except without any
data fields. That internal match data is very compact, containing only match
types and start/end positions. When a match is complete, Rosie calls an output
encoder to transform this internal data structure into a consumable form.
The JSON output encoder produces JSON, naturally, but also inserts the field
called data into each match, and fills in the value by taking the substring of
the input in the interval [s:e] (to use slice notation). See the next
question for how to access the compact internal data representation instead of
the verbose JSON one.
How do I put captures in my RPL pattern?
Rosie has named captures, and they are created implicitly. Let’s step back first and look at regex captures first.
Regex have a simple notion of captures. You put an expression in parentheses, and you will get a capture in the output. I think they are overly simple. Lacking names, captures are numbered, and you have to know how the numbering algorithm works when captures are nested. Extensions to regex allow named captures, and also capturing positions in the input, but support varies across implementations.
Many regex usability issues appear to arise when a developer has a working expression, but they need to change what is captured.
When designing RPL, I saw an opportunity to separate matching from capturing by removing captures from the RPL pattern syntax. RPL patterns are concerned with what to match, not what to capture.
In order to make this happen, I devised a simple rule: If a pattern has a name, that name will label a capture.
This simple rule applies with a caveat: The Rosie alias keyword declares a
macro substitution, so after alias foo = ..., I can write foo and Rosie will
substitute its definition, .... Consequently, an expression using foo
does not contain a pattern named foo, but instead its definition.
The alias keyword provides a way to use a pattern repeatedly without retyping
it, just as substitution macros do in other languages.
Now that we understand alias, we can properly interpret the rule, which says
that every (non-alias) named pattern becomes a named capture in Rosie’s output.
Also, Rosie’s named captures include the start/end byte positions of the captured
text.
It certainly increases the size of the match (result) data structure to retain a
lot of named captures. However, frequent use of the alias keyword reduces
the size of match results. A common development technique I have observed is to
begin without any use of alias, until the pattern being written accepts
the right set of input strings. Then alias keywords are added to remove from
the output the labels that are not semantically interesting.
Is the concept of ‘output encoder’ necessary? Regex does not have these.
With an understanding of how RPL treats captures (see above), we can talk about output encoders. They make it practical to separate matching from capturing. Matching produces an internal data structure that reflects exactly how the pattern is written. (It should be possible to automatically derive an output schema given a pattern. This would be a fun small project for a contributor!)
An output encoder is a function whose argument is an internal match data
structure, which is a tuple type, start, end, subs. The last item, subs, is
a possibly empty list of match data structures. (A match is a parse tree.)
An output encoder could, in theory, produce anything. In practice, Rosie output encoders are constrained to return a byte array which is then interpreted by the caller.
The color output encoder uses a mapping of pattern names to colors to create a
colorized version of the input text. Its output is a byte array meant to be
interpreted as a UTF-8 string containing ANSI SGR escape sequences.
The line encoder returns the input line (like the Unix grep utility
does, by default).
The json encoder produces JSON, of course, and jsonpp produces
pretty-printed JSON.
And, if you want a very compact output that contains the nested match structure
(unlike, say, line), then there is a byte encoder which packs the match
structure into a binary encoding which is easy (and fast) to decode.
Ideally, the Rosie modules for Python, Go, and other languages would call
librosie’s match API asking for byte encoded output, which it would then turn
into a native nested structure like a Python dict or a Go map. This would be an
improvement in efficiency over the current implementation, in which librosie is
asked to produce JSON, which is then decoded by a JSON module. (Here is another
small, fun project for a contributor!)
All of the above add up to why Rosie has the concept of an output encoder. It allows the pattern writer to focus on what will be matched. A separate (orthogonal) concern is how the output will be produced. The encoder receives a complete match data structure, with which it can do anything, including ignore parts (or all) of the match data structure.
RPL looks like overkill. Wouldn’t something simpler work?
Yes, probably something simpler would work. But I’m aiming for longevity. RPL is a language, and it’s really, really inconvenient for users when a language changes. RPL is neither perfect nor future-proof, but I hope that the language itself will not need to change for a long time. The compiler and run-time can be improved, new libraries can be added, and new macros and output encoders can be added – all without changing the RPL language specification.
RPL has modules because they are semantically important and I didn’t want to
retrofit them later in order to facilitate sharing of patterns. (RPL is ready
for a contributor to implement a Rosie version of go get!)
RPL has macros because, as in other languages, they provide a convenient syntax for some expressions that would be cumbersome otherwise. User-defined macros can be added in the future without changes to the RPL syntax.
In short, all the features of RPL were designed so that certain kinds of enhancements can be made in a strictly backwards-compatible way.
Performance
How should we measure match performance? Rosie must compile an RPL pattern, read the input, perform the matching, encode the output, and write the encoded output. An “end to end” measurement would include all of these steps.
But Rosie was designed to handle lots of data, which implies that a pattern will be compiled once and used a great many times, making compilation times insignificant when amortized.
Also, while today RPL is compiled on the fly, in the future you will be able to compile it ahead of time. Then, when needed, a compiled pattern will be loaded from disk. I expect the load times to be orders of magnitude smaller than compilation times. This is, perhaps, another reason to consider compilation times separately – because they will be replaced by load times.
In the next sections, let’s look at the way things are today, in version 1.0.0.
Compilation performance
Rosie’s compiler is slow. It’s written in Lua, which is fast for an interpreted language, but my code generates lots of intermediate data (mostly for debugging the RPL compiler), which taxes the garbage collector. My code also contains lots of assertions, and these are slow in Lua.
Furthermore, the current RPL compiler inlines all patterns. If you build a
sequence like bar = foo foo foo, the resulting pattern, bar will contain 3
copies of foo. Even though foo is compiled only once, it takes time and
space to concatenate its instructions 3 times in order to build bar. The plan
is to change this by improving the RPL compiler. The change will not be visible
externally, except in faster compile times and reduced memory requirements.
Match performance
Librosie’s match API is instrumented, returning the number of microseconds
consumed by matching and encoding together, and (separately) consumed by
matching only.
At some point I may write up an analysis of matching time, but the instrumentation is there so that anyone can measure the relative effects of different patterns and different output encoders.
A very limited bit of profiling has revealed some optimizations that could be made in the matching virtual machine. Perhaps more impact, however, would come from enabling the RPL compiler to do more optimizations, to produce more efficient programs for the vm.
In terms of comparisons, it’s hard to compare Rosie to other pattern matchers.
It would be best to compare Rosie with other PEG implementations, but this is
awkward when those implementations are language-dependent. I should measure
Rosie’s Python interface against another PEG-based Python library. And Rosie’s
go interface against a PEG-based go library. Etc. But then I’m measuring the
quality of the Rosie module and how well it uses the FFI library – and these
are things that have not been tuned at all. (If you are a Python/ffi person, or
a go/cgo person, we could use your help to improve rosie.py and rosie.go!)
Comparing to regex matchers feels wrong because PEGs are more powerful. It might be nice to have a set of tests that restrict Rosie to patterns that have a regex equivalent. On the other hand, this would illuminate only the performance trade-off of using Rosie instead of a particular regex engine. It would not measure the savings in development and the reduction in run-time errors that we expect Rosie to provide.
Still, matching performance is important. Rosie comes out 4-5x faster than grok running in jRuby. Comparing to grok seemed useful because both grok and Rosie allow you to build up a library of named patterns, and both are designed to compile up front and then use the compiled patterns many times. Also, the fact that Rosie was considerably faster with its PEG basis than grok with its regex basis was gratifying. The power of PEGs does not imply bad performance.
The graph below is from 2016. Updating it for Rosie version 1.0.0 is on the “to do”
list.
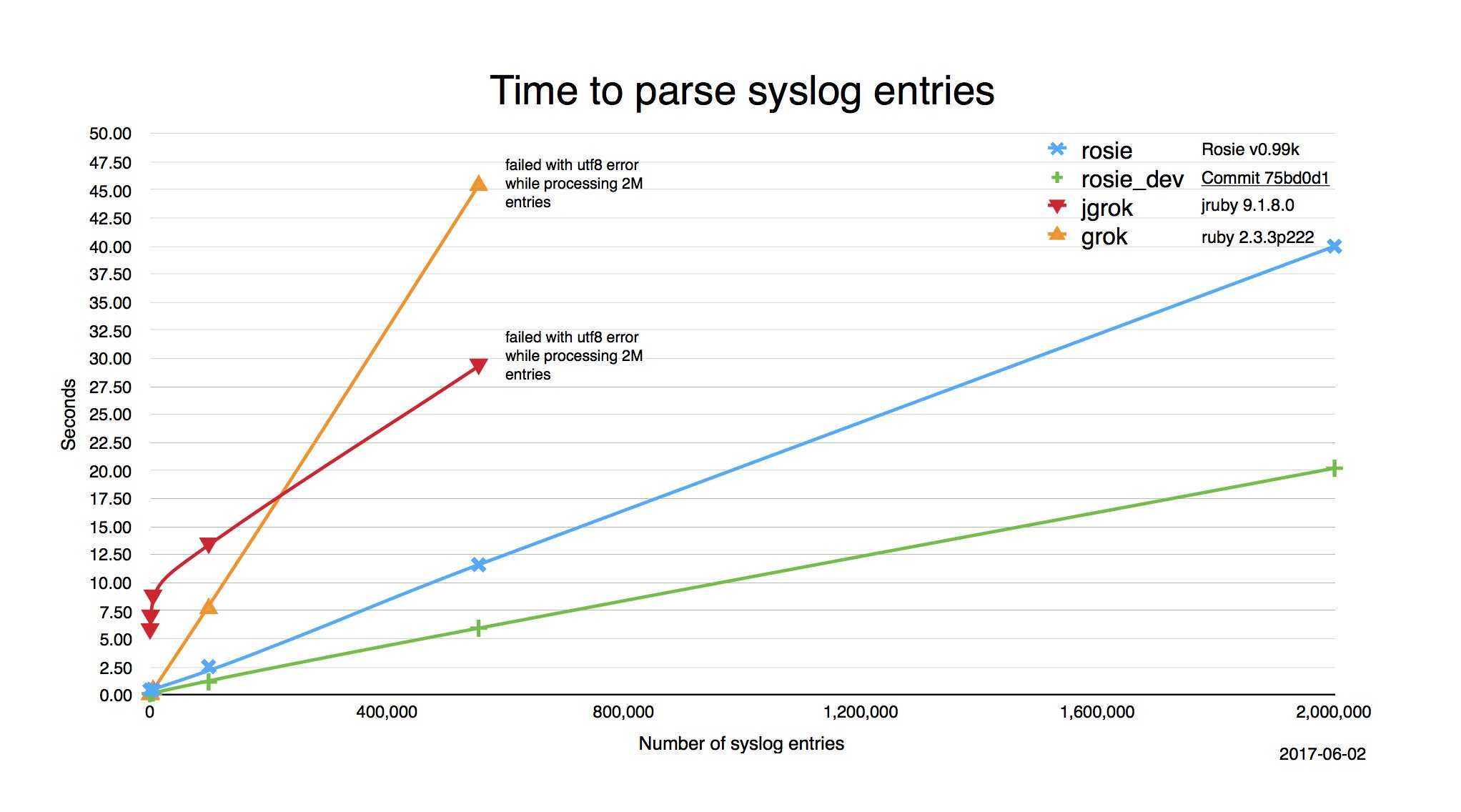
I have not compared the matching performance of Rosie with other systems, whether PEG-based or regex-based. I would be happy to collaborate with a contributor on such a study, though!
Output encoding performance
Several of Rosie’s output encoders are written in C and are fairly fast, like
byte, line, and json. Other encoders, like jsonpp and color are
written in Lua and are quite slow by comparison.
It’s a good thing, and no coincidence, that pretty-printed JSON and colorized output are meant to be read by humans, so they don’t have to be fast.
But the existence of a variety of output encoders means that performance tests must either choose one or add a test dimension to accommodate all of them.
I have not studied the relative performance of output encoders. It would make a
good (small) project for a contributor, though! The instrumentation already in
place on librosie’s match API should be sufficient to take measurements.
Current State of the Project
RPL language
The RPL language is versioned separately from Rosie. The current version is RPL 1.2, and is stable. This version is intended to be a semantic version with only major and minor components. RPL may evolve in a strictly backwards compatible way, and when it does, we will increment the minor version (to 1.3, etc.).
I hope that it will be a long time before RPL 2.0 is needed, since this would imply a lack of backwards compatibility.
Librosie
The librosie API includes all the essential Rosie functions. More functions,
primarily for convenience, could be added if there is a need. For example, it
would be convenient if librosie provided a way to extract unit tests from RPL
files, and to execute them as the Rosie CLI test command does.
Librosie needs documentation as of this writing (February, 2018). Currently, the sample programs in C (there are 3), Python, and go serve as illustrations of how librosie can be used.
Rosie’s version will be incremented when librosie changes. Internal changes and bug fixes will increment the patch version (e.g. to 1.0.1). New functionality that is backwards compatible will increment the minor version (e.g. to 1.1.0).
Rosie CLI
Rosie’s CLI includes all essential functions, plus the ability to process an
initialization file (by default ~/.rosierc) and to run unit tests. Also, the
CLI contains an interactive read-eval-print loop (REPL) interface.
Notably missing from the CLI are options to walk through the filesystem, and options to specify how certain files should be processed. For example, should binary files be skipped? Should symbolic links be followed?
Such missing features prevent Rosie from being an easy replacement for Unix grep. Still, Rosie is easy to use in scripts as a grep replacement, and it’s not too bad at the command line either, unless you use lots of the specialized grep options.
Even though RPL is more verbose than regex, I can envision using Rosie instead of grep most of the time. I’m willing to type a few extra quote marks and spaces to be able to search like this, with output that can be switched between human-readable, JSON, or simply the matched text:
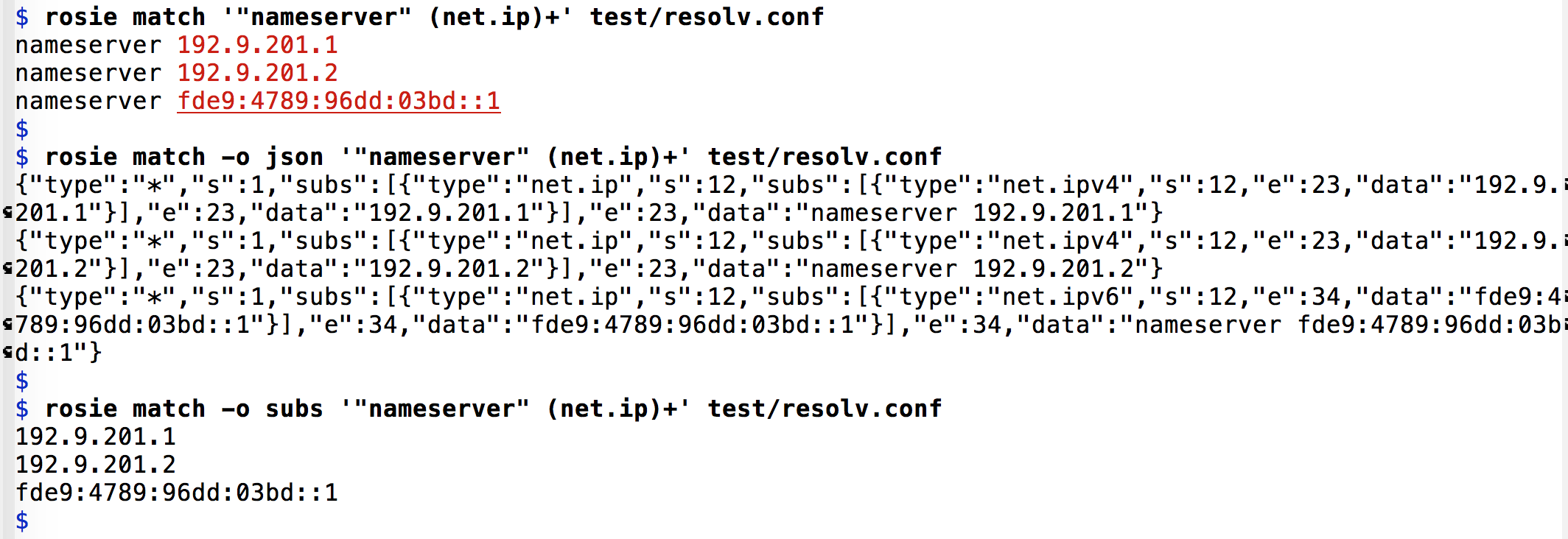
Roadmap (near term)
This (long) blog post mentions some places that I’d like to take Rosie, with help from contributors. In addition, here are a few items that are on the roadmap for 2018:
- Improve the documentation.
- Save compiled patterns to disk; load them when they are imported, instead of recompiling.
- Separate the matching vm (run-time) and the compiler so that the run-time can be used separately.
- Speed up the compiler by reducing the amount of intermediate data it retains, removing unneeded assertions, and other refactoring.

Grand vision
Since this post has some attributes of a manifesto, I will finish with some thoughts on the grand vision for Rosie and RPL.
First and foremost, I’d like to see RPL used in software that today rely on a non-trivial amount of regex. RPL is meant to be easier to develop and (especially) maintain over time. By compiling and unit-testing RPL, errors can be caught before deployment. Finally, RPL plays well with devops tools, in the form of better diffs, dependency management, and the unit tests already mentioned.
That goal can be taken further. I’d like to see every text format ship with an RPL package that can read it. If your software writes data in a non-standard format to a file, you should (1) use Rosie to read it back in, and (2) publish the RPL so that other people can read your data. This opens up the ecosystem around your product, allowing people to build tools that read your system’s output and do inspired and useful things with it.
Sometimes we write systems to output XML or JSON or some other structured format, because we expect this data to be read by another program. But the point here is that sometimes we don’t use a standard format. Often that is when the data we write is for human consumption. A common example is the message field of a log entry.
Another example is a configuration file which is written and read by a single software system. We don’t anticipate that anyone else would want to read our private format. Often, however, someone is going to try to read our configuration file, perhaps to make sure the settings are correct. Or perhaps to change a setting. Or maybe they have something more innovative in mind. But leaving them to write their own parsers is an obstacle to achieving any of these objectives. By sharing the RPL pattern that reliably reads such a file (ignoring comments, and interpreting the syntax correctly), you can help your users do new and interesting things.
I’ll mention one more piece of the vision for RPL. Natural language processing usually starts with a set of (regex) patterns for tokenizing the input. These expressions are usually written once and they don’t need changing. The place where RPL can help is when NLP intersects with domains that have detailed, cryptic notation.
Examples abound, from medical notes to architecture/construction text to research data to insurance documents to drug prescriptions. Input text from all of these areas and others contain both natural language and also highly domain-specific notations.
Many notations have a simple grammar, like bis in 7d., or D5W, which, when written on a prescription, mean “twice a week” and “dextrose 5% in water”, respectively. RPL is useful because the 7 and the 5 in these simple examples can vary. So perhaps we should write patterns to recognize these notations with any number in their place. (We could do this with regex, but we would end up with a long list of expressions that have all the maintenance and share-ability problems of regex.)
In this age of easy access to machine learning, perhaps there are already high quality domain-specific adaptations of NLP to fields with specialized notation. An approach based on RPL would have many advantages, in my view. Not least is that packages of domain-specific RPL patterns could be shared and used for many purposes, not just NLP. For example, they could be used for input validation in any software made for that domain.
Feedback
Edit August 15, 2023: We briefly had a sub-reddit for Rosie project discussions, but it has fallen out of use. And, I am no longer regularly using the site formerly known as Twitter. Please feel free to provide feedback by any of these means:
- My Mastodon and other contact information is on my personal blog.
- If you find any issues installing or using Rosie, please open an issue on GitLab.
- Or, you can email us directly at info@rosie-lang.org.
Notes
-
Quoted in http://regex.info/blog/2006-09-15/247 with this attribution: “jwz@netscape.com wrote on Tue, 12 Aug 1997 13:16:22 -0700…”. ↩︎
-
Ken Thompson, “Regular expression search algorithm,” Communications of the ACM 11(6) (June 1968), pp. 419–422. This paper is occasionally cited incorrectly as the invention of regular expressions. Thompson did not invent or discover them. The paper is the first to describe an NFA-based implementation for matching regular expressions, one which does no backtracking. The compact and efficient compilation and matching techniques described in the paper made regular expressions a practical (and powerful) technique for text searching in utilities like grep, sed, awk, and many text editors. ↩︎
-
I don’t speak for IBM, and nothing I say here should be taken as a product announcement or anything like that. The IBM Cloud offering allows developers to use a wide variety of open source and third-party tools for source code management, issue management, test and build automation, etc. I was on a team building analytics for the devops process. I looked at the challenges we might face in mining the output of dozens of devops tools, knowing that (1) those tools would evolve, and their output would change over time, and (2) new tools would be supported in the future. Rosie/RPL was my solution to the frustration caused by using regex as the foundation for this data mining. The product I worked on eventually became IBM Cloud Devops Insights. ↩︎
-
With alarming frequency, developers ask online how to use regex to parse recursively defined data like HTML/XML. Of course, it is not possible using actual regular expressions (though many implementations provide a variety of extensions, which varying degrees of success). The best answer to such a posted question is, without a doubt, this one (click the image to see the full post… it’s worth it):
 ↩︎
↩︎ -
“A type system for regular expressions” by Eric Spishak, Werner Dietl, and Michael D. Ernst. In FTfJP: 14th Workshop on Formal Techniques for Java-like Programs, (Beijing, China), June 2012, pp. 20-26. ↩︎
-
A good overview of Parsing Expression Grammars may be found on Wikipedia. Bryan Ford introduced the PEG formalism in 2004, and demonstrated that it is strictly more expressive than regular expressions, but less so than Context Free Languages. ↩︎
-
Roberto Ierusalimschy created the PEG implementation called lpeg. In this paper on LPEG, Ierusalimschy describes an elegant virtual machine for parsing using PEGs. The approach yields a
linear time (in the input size)matching algorithm that, due to optimizations, often requires only constant space (rather than linear space). Moreover, he notes that the implementation does very well in benchmarks. In the Rosie project, I have simplified the lpeg virtual machine in some ways, and enhanced it in other ways, to better align with the Rosie Pattern Language. ↩︎ -
I work for IBM but I do not speak for them. In this and in other writing about Rosie and RPL, I speak only for myself. (Edit on August 15, 2023: As of 2018, I no longer work for IBM.) ↩︎
-
Sérgio Medeiros, Fabio Mascarenhas, Roberto Ierusalimschy, “From regexes to parsing expression grammars”, Sci. Comput. Program. 93: 3-18 (2014). ↩︎
-
I supervised the project, and we expect to release an enhanced version of the code in the future. ↩︎