
Project activity 2021-2023
The last few years have seen annual releases of Rosie with minor improvements. During this time, we have been re-architecting the project to achieve some ambitious goals that we did not have when the project began. Skip ahead to read about that.
New website format!
Rosie has a new website format! We switched to the static site generator Hugo, and changed the format to make this site a suitable home for Rosie documentation, which is currently on GitLab, with the Rosie source code.
Over the coming months, we will migrate that documentation to this site, improving its organization in the process.
Release of “Rosie 1.4.0”
On August 17, 2023, we released Rosie 1.4.0. A minor new feature is the addition of a new output encoder: Rosie can now produce S-expression output, an elegant and concise way of representing trees and lists. With the help of Emacs' ability to properly indent S-expressions, the output looks like this:
$ date | rosie match -o sexp date.any
("date.any" 1 12 "Thu Aug 17 "
("date.us_long" 1 12 "Thu Aug 17 "
("date.day_name" 1 4 "Thu"
("date.day_shortname" 1 4 "Thu"))
("date.month_name" 5 8 "Aug"
("date.month_shortname" 5 8 "Aug"))
("date.day" 9 11 "17")))
$
A more significant feature is the ability to perform case-insensitive matches on strings from any Unicode script.
The ci: macro, already part of Rosie, used to understand only the ASCII subset
of UTF-8. It would match strings with ASCII characters of different cases, but
any non-ASCII UTF-8 characters must match exactly.
The new functionality in this release includes:
- The
ci:macro understands upper, lower, and title case mappings for all Unicode characters. - A new macro,
cfs:, implements Unicode’s simple case folding data to produce a case-insensitive pattern. - A new macro,
cff:, implements Unicode’s full case folding data to produce a case-insensitive pattern.
The simple and full case folding algorithms are defined in the Unicode standard. The simple algorithm is a one-for-one substitution that does not change the number of characters in a string. The full algorithm, by contrast, can handle the substitution of the German “sharp s”.
In the example below, we can see the following:
- The
ci:macro generates a case-insensitive match using basic Unicode case information, as shown for the Greek οδός. Basic case mapping includes characters from the Latin script, such as those in strasse. - The
ci:macro fails to find case mappings for the “sharp s” in the German word Straße. Unicode simple case folding data is needed here, and we see that thecfs:macro matches the (oddly written) input in which the “sharp s” is in upper case, Straẞe. - The ability to substitute ss or SS for the lower and upper case “sharp s”
is captured in the Unicode full case folding data, which is used only by the
cff:macro as shown in the last item in the example.
$ rosie match 'ci:"οδός"' <<< "ΟΔΌΣ"
ΟΔΌΣ
$ rosie match 'ci:"strasse"' <<< "Strasse"
Strasse
$ rosie match 'ci:"Straße"' <<< "Straẞe"
$ rosie match 'cfs:"Straße"' <<< "Straẞe"
Straẞe
$ rosie match 'ci:"Straße"' <<< "StraSSe"
$ rosie match 'cfs:"Straße"' <<< "StraSSe"
$ rosie match 'cff:"Straße"' <<< "StraSSe"
StraSSe
$
In a future blog post, and in the Rosie documentation, we will provide a more expansive explanation of these features.
Rosie 2.0
In 2021, we began a multi-year effort to redesign the Rosie implementation to facilitate work on the following goals:
- Experiment with new language features;
- Reduce maintenance and packaging effort supporting a mix of Lua and C code; and
- Improve performance.
New language features
After much experimentation, we are close to choosing which features will be added to the forthcoming “Rosie 2.0”.
We have already removed some limitations that are common to most PEG implementations, including lpeg, on which Rosie was initially based. For example, our language now supports repetitions of patterns that may match the empty string. And, our language now supports look-behind with target patterns that can have variable length.
The back-reference feature, which is currently an experimental one in Rosie 1.4.0, will be fully supported in the new language.
Other features, which we are not yet ready to describe, will facilitate writing commonly-needed pattern expressions.
Much of this work takes the Rosie Pattern Language well beyond the PEG specification. We think this is appropriate, since few PEG implementations follow it. The utility of Parsing Expression Grammars lies not in its fit for purpose, clearly, since extensions are necessary. And the linear-time Packrat parsing algorithm for PEGs is rarely used because of large space requirements. What is left? Personally, I suspect that what draws developers to PEGs is their imperative nature. A PEG grammar reads like a sequence of instructions on how to match its input, unlike a regex which appears more declarative and thus requires the programmer to maintain a more complex mental model of the regex engine. Perhaps we shall explore this topic in a future post.
Reduced maintenance
From the inception of the Rosie project at IBM in 2015, we built on top of lpeg, which meant that embedding Lua was a requirement (because the lpeg code leverages Lua internals, particularly data structures like tables and strings). Since Lua would be embedded in Rosie, it was natural to write a good deal of Rosie in Lua.
Lua is a wonderful language (much better than Python, to which it is often compared), but it is an evolving language. New releases regularly bring breaking changes, creating a porting effort for us if we want to keep up. So we froze our embedded Lua at version 5.3.2. We do not expose Lua to Rosie users; having the latest version was not necessary. But embedding another project does require us to keep up with bug fixes for Lua and the Lua libraries we use, such as for JSON and readline support. For “Rosie 2.0”, we seek a simpler code base, with only one language to support.
Had we started the new code base when Rust was as stable as it is today in 2023, we would surely be writing in Rust. In 2021, it was not clear whether this would be the case, and so we began in C99. Writing in C, though perilous, has some advantages. First, we could reuse code we had written for earlier versions of Rosie. Second, the tools for C have grown quite good in the last 10 years or so, especially around memory use analysis and detection of undefined behavior. Third, we knew we would have easy access to intrinsics for CPU vector operations. Finally, platform support would never be an issue, though it does require effort in any “systems” language.
Performance
Our new pattern compiler incorporates traditional optimizations such as tail recursion elimination, function inlining, and loop unrolling. Along with some new VM instructions and enhancements to the code generator, we are seeing performance that is consistently better than both Rosie 1.3 and lpeg 1.0.1.
In the graph below, the “Rosie 2.0” code is labeled using its code name, pexl
(parsing expression language). Time is on the y-axis, so lower is better. All
three systems dynamically load their libraries using dlopen, and they all read
the entire input into memory before compiling a pattern and performing a search
with it. Each group of bars is labeled by the pattern name for that test. The
patterns are defined in this
paper.
The results shown here require that all occurrences of the pattern be found in the 4.1Mb input file, and further that the start and end positions for each occurrence be captured.
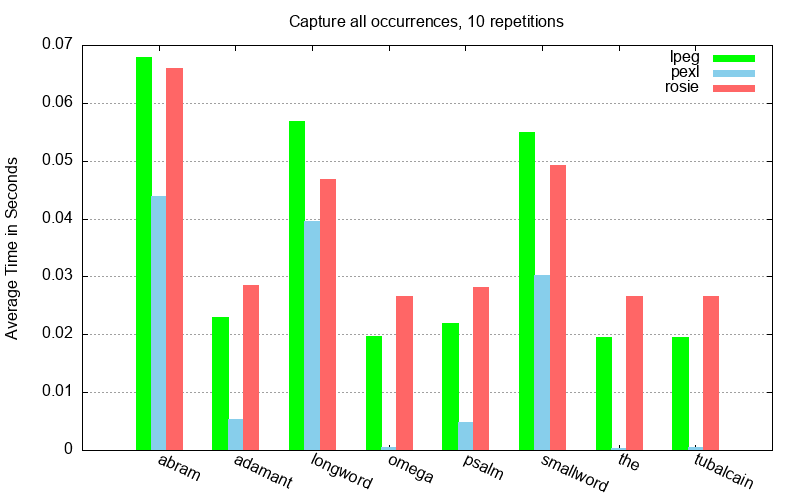
Note that for the patterns omega, the, and tubalcain, the pexl bar is
almost too small to see. Performance on such patterns has been dramatically
improved (and without the use of CPU vector instructions).
Not shown here is that the new code base uses significantly less memory than either Rosie or lpeg. More performance (space and time) results are coming in future posts.
We welcome feedback and contributions. Please open issues (or merge requests) on GitLab, or get in touch by email.
You can find my contact information, including Mastodon and LinkedIn coordinates, on my personal blog. The mailing list https://groups.io/g/rosiepattern has fallen out of use since we mostly use Slack, but perhaps it will be revived.